Our Methodology
Forecast Valley uses a rigorous, data-driven approach to deliver accurate and scalable forecasting solutions, summarized below:
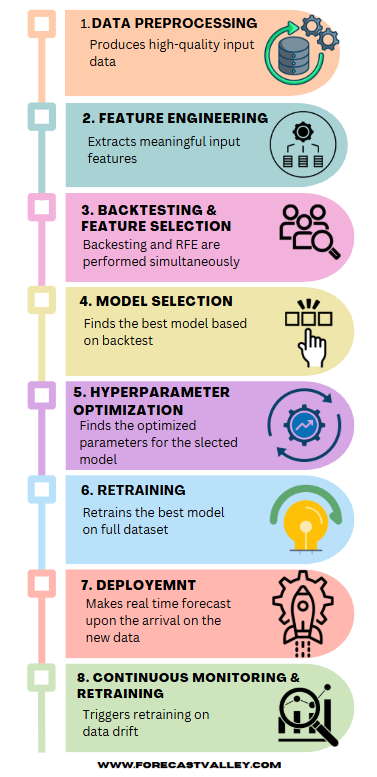
Data Preprocessing
Datasets are cleaned and prepared, missing values are handled through imputation, and outliers are detected and treated to ensure high-quality input data.
Feature Engineering
Predictive features, including lagged values, moving averages, seasonal indicators, and domain-specific external predictors are extracted to capture patterns that drive accurate forecasts.
Backtesting & Feature Selection
Forecasting models—from classical statistical approaches to advanced machine learning algorithms—are rigorously backtested on historical data while Recursive Feature Elimination (RFE) is applied to remove features that do not improve accuracy. Metrics such as R², RMSE, MAE, and MAPE are used to identify the optimal model and feature combination.
Model Selection
The best-performing model and feature set are confirmed based on backtesting and RFE results to ensure accuracy, stability, and generalization across different time horizons.
Hyperparameter Optimization
Model hyperparameters are fine-tuned using grid search, randomized search, or Bayesian optimization to maximize accuracy while minimizing overfitting.
Retraining
Models are retrained on the full dataset with optimized parameters and selected features to capture all temporal patterns, strengthening predictive power and resilience to data drift. At this stage, the model is fully trained and ready to make real time forecast.
Deployment
Models are deployed into automated, scalable pipelines supporting real-time forecasting upon arrival of the new data in real time. Logging, monitoring, and API endpoints are integrated to ensure smooth and reliable operation.
Continuous Monitoring & Retraining
Performance is continuously tracked, and retraining is triggered when data drift is detected or the accuracy falls under a certain threshold, maintaining long-term reliability and forecast accuracy.